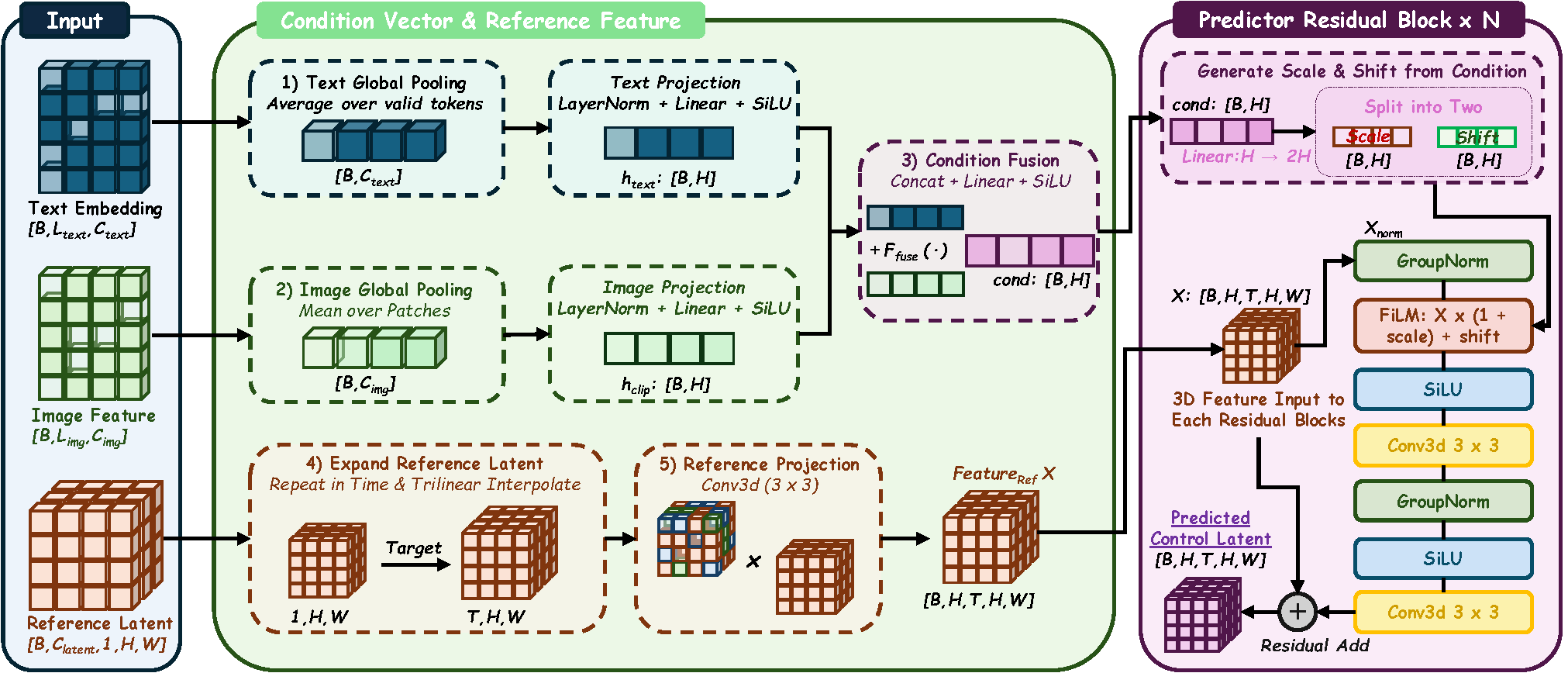
With the rapid progress of video generation models, researchers have begun to explore whether they can serve as simulators of the physical world. Existing methods usually rely on external simulators to generate explicit motion proxies, such as point clouds, particles, or trajectories, which are then projected into the video domain and refined by a video generator. Another line of work translates motion information into simplified or pixel-space control conditions to guide the video generator. Despite different pipelines, both paradigms ultimately rely on projected motion cues, which provide limited support for modeling material responses under changing interactions. Our key insight is that constitutive-state representations can bridge this gap by describing the material response that links external interactions to deformation and motion. We present PhysWonder, a unified framework for physically controllable video generation built around simulation-coupled constitutive-state representations. Our framework consists of PhysWonder-3D, which enables unified constitutive simulation and scalable physically grounded data synthesis through a decomposition-based hybrid Material Point Method, and PhysWonder-Ctrl, which uses a dual-branch video generation architecture to internalize deformation-gradient-based constitutive-state control. By treating deformation gradients as constitutive-aware supervision, joint training strengthens deformation-gradient control and learns constitutive-aware latent control without requiring explicit control videos during inference. Experiments show that PhysWonder achieves state-of-the-art synthesis efficiency and robustness among simulator-coupled baselines, and improves controllability, fidelity, and motion consistency under both explicit deformation-gradient control and control-free inference.
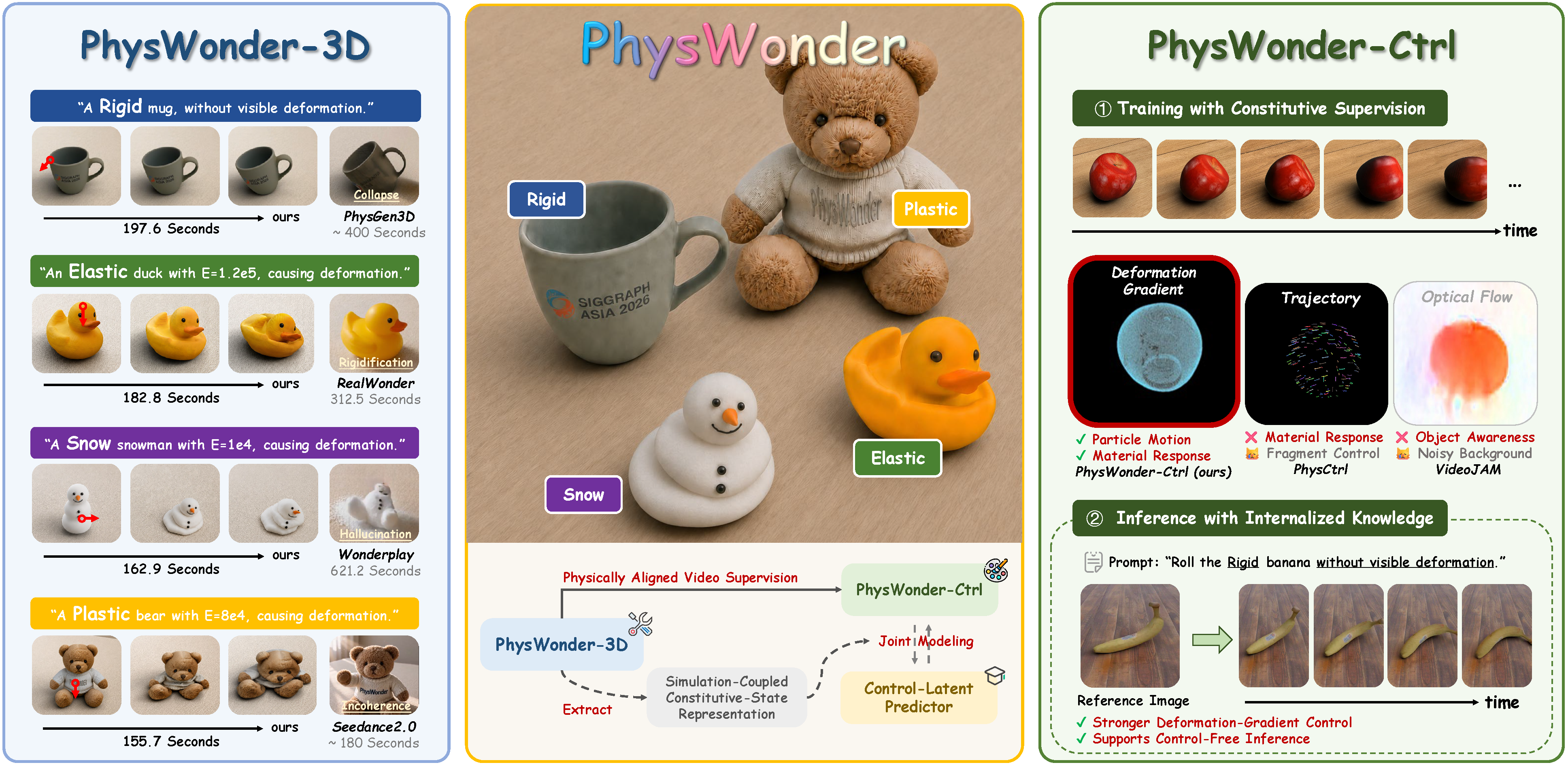

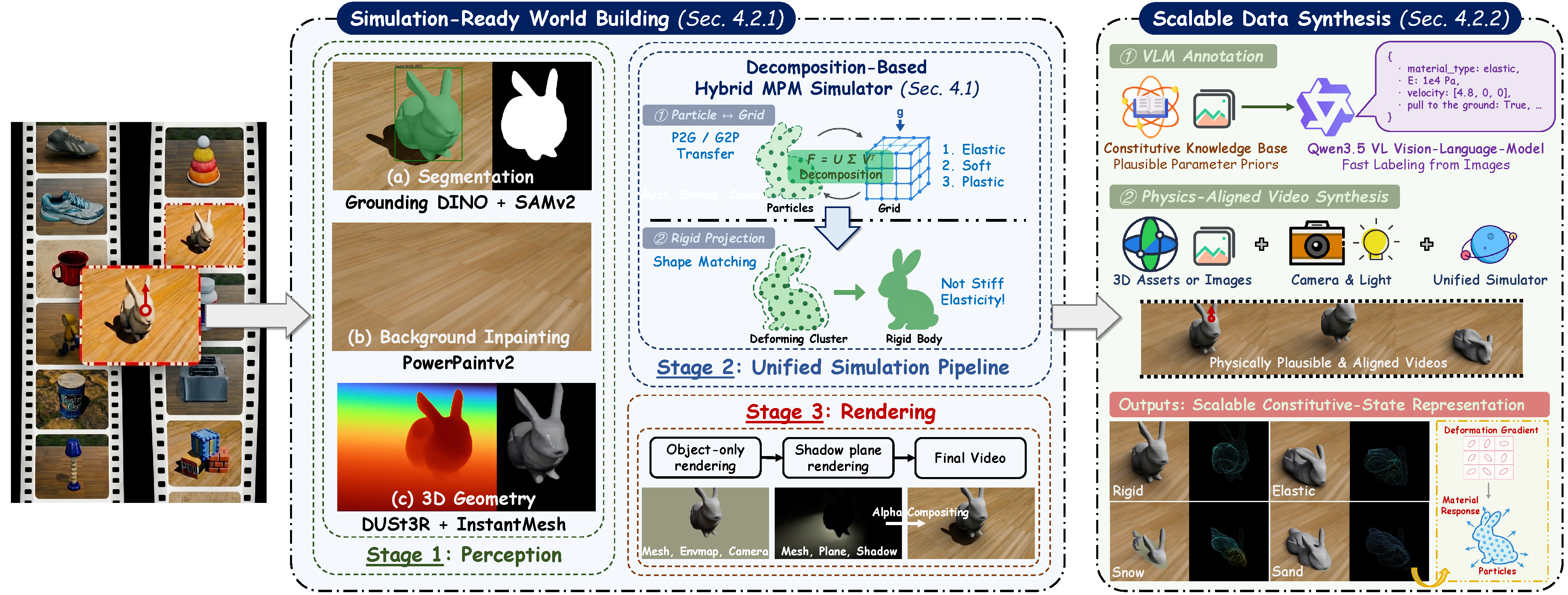
We introduce a decomposition-based hybrid MPM formulation, which forms the core of PhysWonder-3D, a unified constitutive simulation and scalable data synthesis pipeline. It unifies diverse material behaviors within a single particle-grid simulator, achieving the best efficiency and success rate while producing high-fidelity videos and unique deformation-gradient representations of particle-level motion and material response.




 Elastic
Elastic

 Elastic
Elastic



 Elastic
Elastic


 Rigid
Rigid

 Rigid
Rigid


 Rigid
Rigid


 Sand
Sand



 Elastic
Elastic



 Sand
Sand



 Snow
Snow



 Elastic
Elastic


 Elastic
Elastic| Method | Elastic ↓ | Rigid ↓ | Sand ↓ | Snow ↓ | Succ. ↑ |
|---|---|---|---|---|---|
| PhysGen3D | 490.6 | -- | 369.7 | 402.4 | 7/12 |
| WonderPlay | 579.5 | 599.8 | 598.2 | 621.2 | 4/12 |
| PerpetualWonder | 6755.6 | 11972.9 | 6745.6 | 9355.4 | 4/12 |
| RealWonder | 312.5 | 344.8 | 282.8 | 299.9 | 8/12 |
| PhysWonder-3D | 182.8 | 197.6 | 155.7 | 162.9 | 12/12 |
We propose PhysWonder-Ctrl, a joint modeling framework for video generation with internalized constitutive control. We leverage deformation gradients as a distinctive simulation-coupled constitutive representation, jointly optimizing the control-latent predictor and video generator for material-response-aware generation. Experiments demonstrate strong physically controllable video generation and support deformation gradients as internalizable constitutive representations, while the learned predictor enables inference without explicit control videos.
Same image. Same motion. Different material response.
"An elastic banana with Young's modulus E=400000 starts on the ground, initially moving to the right, causing deformation."





"A rigid banana starts on the ground, initially moving to the right, without visible deformation."





"A sand chocolate with Young's modulus E=10000 starts on the ground, initially moving to the right, causing deformation."






"A snow chocolate with Young's modulus E=40000 starts on the ground, initially moving to the right, causing deformation."



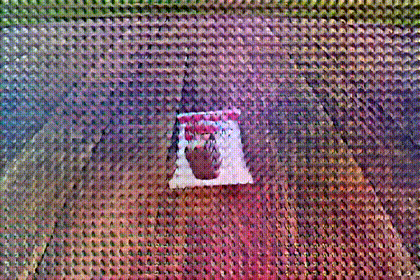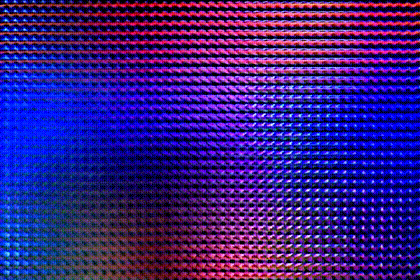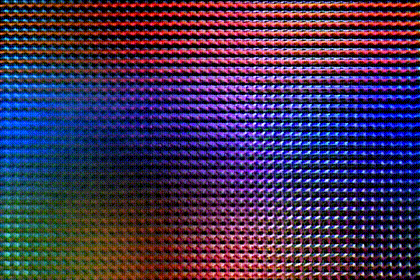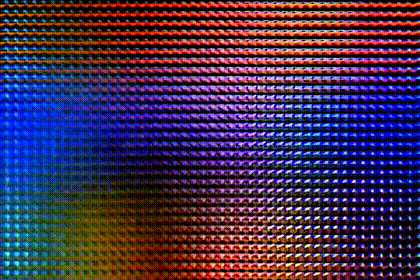


| Category | Method | PSNR ↑ | SSIM ↑ | LPIPS ↓ | SimFlow ↑ |
|---|---|---|---|---|---|
| Physics-Guided Models | Force-Prompting-5B + Perfect Prompt Only | 9.99 | 0.0899 | 0.8832 | 0.0189 |
| VideoREPA-5B + Perfect Prompt Only | 23.38 | 0.6345 | 0.2626 | 0.0675 | |
| Foundation Models (w/o Fine-Tuning) | Wan2.1-TI2V-1.3B + Perfect Prompt Only | 20.41 | 0.5345 | 0.5642 | 0.0432 |
| Wan2.2-TI2V-14B + Perfect Prompt Only | 20.42 | 0.5351 | 0.5645 | 0.0423 | |
| Wan2.1-TI2V-1.3B + GT Deformation-Gradient Control | 23.82 | 0.6167 | 0.2659 | 0.3165 | |
| Wan2.2-TI2V-14B + GT Deformation-Gradient Control | 23.66 | 0.6179 | 0.3124 | 0.2985 | |
| Ablation (Control Fine-Tuning) | Wan2.1-TI2V-1.3B + Perfect Prompt Only | 20.35 | 0.5274 | 0.6088 | 0.0182 |
| Wan2.1-TI2V-1.3B + GT Trajectory Control | 23.59 | 0.6303 | 0.2484 | 0.2756 | |
| Wan2.1-TI2V-1.3B + GT Optical Flow Control | 20.56 | 0.4795 | 0.6645 | 0.2307 | |
| Wan2.1-TI2V-1.3B + GT Deformation-Gradient Control | 24.24 | 0.6463 | 0.2314 | 0.3398 | |
| Ours (Joint Modeling) | PhysWonder-Ctrl-1.3B + GT Deformation-Gradient Control | 24.50 | 0.6513 | 0.2301 | 0.3575 |
| PhysWonder-Ctrl-1.3B + Latent Predictor w/o GT Deformation-Gradient Control | 23.77 | 0.6359 | 0.2485 | 0.3410 |
Deformation-Gradients provide more effective constitutive control than motion-level signals
All control-representation comparisons use the same training-data scale. Trajectory controls and deformation-gradient controls are directly obtained from PhysWonder-3D simulation with exactly the same particle count, while optical-flow controls are extracted from the rendered ground-truth videos. As a result, trajectory and optical flow serves as an upper-bound reference for motion-level control methods such as PhysCtrl and VideoJAM.
PhysWonder-3D Engine-in-the-loop
Gradient
Flow
PhysWonder-3D Engine-in-the-loop
Gradient
Flow
PhysWonder-3D Engine-in-the-loop
Gradient
Flow
PhysWonder-3D Engine-in-the-loop
Gradient
Flow
Can the Control Latent Predictor Learn Material-Response Aware Controls?
Using the same backbone and training data, we compare PhysWonder-Ctrl with a prompt-only fine-tuned baseline. At inference time, both methods rely only on the reference image and text prompt, without explicit deformation-gradient videos. PhysWonder-Ctrl produces more material-aware dynamics, including shape-preserving rigid motion, visible elastic deformation, and plastic collapse or spreading, suggesting that it learns deformation-informed latent controls beyond simple prompt tuning.
"A Sand water cup with Young's modulus E=4000 starts on the ground, initially moving to the right, causing deformation."
Prompt Only
"A Snow alcohol with Young's modulus E=1000 starts on the ground, initially moving to the right, causing deformation."
Prompt Only
"An Elastic banana with Young's modulus E=10000 starts on the ground, initially moving to the top, causing deformation."
Prompt Only
"A Rigid donut starts on the ground, initially moving to the right, without visible deformation."
Prompt Only
| Metric | Seedance 2.0 | Wan2.1-TI2V-1.3B | PhysWonder-3D | PhysWonder-Ctrl GT Deformation-Gradient |
PhysWonder-Ctrl Predicted Control Latent |
|---|---|---|---|---|---|
| DiffSSIM ↑ | 0.38 | 0.00 | 0.33 | 0.29 | 0.21 |
| DiffCLIP ↑ | 1.02 | 1.00 | 1.11 | 1.06 | 1.04 |
| VLM Wins ↑ | 1.6/4 | 0.1/4 | 4.0/4 | 3.0/4 | 1.3/4 |
We presented PhysWonder, a framework that connects constitutive simulation with physically controllable video generation. PhysWonder-3D provides efficient engine-in-the-loop synthesis across diverse materials, while PhysWonder-Ctrl internalizes deformation-gradient-based control for material-aware dynamic generation. Within our planned computational budget, experiments validate the proposed constitutive-state representation and joint modeling framework, demonstrating material-response control beyond motion-level guidance. PhysWonder remains partly limited by pretrained upstream modules, whose errors may affect world building and output quality. Future work includes scaling to larger generative models and developing engine-in-the-loop evaluation into a more objective protocol for physical consistency assessment. More broadly, our physically aligned synthesis pipeline may support deformable manipulation, flexible grasping, and material-aware planning.